
Strava is getting some bad press, because its heatmap can be used to infer the existence and floorplan of various US/UK military and govt sites.
I covered this briefly in my Berlin Buzzwords 2016 Household INFOSEC talk , though not into that much detail about what's leaked, what a Garmin GPS tracker is vulnerable to (Not: classic XML entity/XInclude attacks, but a malicious site could serve up a subverted GPS map that told me the local motorway was safe to cycle on).

Here are some things Strava may reveal
- Whether you run, swim, ski or cycle.
- If you tell it, what bicycles you have.
- Who you go out on a run or ride with
- When you are away from your house
- Where you commute to, and when
- Your fitness, and whether it is getting better or worse.
- When you travel, what TZ, etc.
How to lock down your account?
I only try to defend against drive-by attacks, not nation states or indeed, anyone competent who knows who I am. For Strava then, my goal is: do not share information about where my bicycles are kept, nor those of my friends. I also like to not share too much about the bikes themselves. This all comes secondary to making sure that nobody follows me back from a ride over the Clifton Suspension Bridge (standard attack: wait at the suspension bridge, cycle after them. Standard defence: go through the clifton backroads, see if you are being followed). And I try to make sure all our bikes are locked up, doors locked etc. The last time one got stolen was due to a process failure there (unlocked door) and so the defences fell to some random drug addict rather than anyone using Strava. There's a moral there, but it's still good to lock down your data against tomorrow's Strava attacks, not just today's. My goal: keep my data secure enough to be safe from myself.
- I don't use my real name. You can use a single letter as a surname, an "!", or an emoji.
- And I've made sure that none of the people I ride regularly do so either
- I have a private area around my house, and those of friends.
- All my bikes have boring names "The Commuter", not something declaring value.
- I have managed fairly successfully to stay of the KoM charts, apart from this climb which I regret doing on so many levels.
I haven't opted out of the Strava Heatmap, as I don't go anywhere that people care about. That said, there's always concerns in our local MTB groups that Strava leaks the non-official trails to those people who view stopping MTB riders as their duty. A source of controversy.
Now, how would I go for someone else's strava secrets?
You can assume that anyone who scores high in a mountain bike trail is going to have an MTB worth stealing, same for long road climbs.
- Ride IDs appear sequential, so you could harvest a days' worth and search.
- Join the same cycling club as my targets, see if they publish rides. Fixes: don't join open clubs, ever, and verify members of closed clubs.
- Strava KoM chart leakage. Even if you make your rides private, if you get on top 10 riders for that day or whatever, you become visible.
What is interesting about the heat map, and not picked up on yet, is that you can potentially deanonymize people from it.
First, find somewhere sensitive, like say, The UK Faslane Nuclear Submarine Base. Observe the hot areas, like how people run in rectangles in the middle.
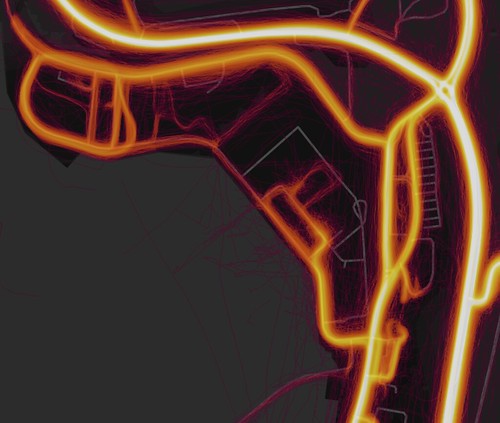
Now, go to MapMyRide and log in. Then head over to create a new route using the satellite data
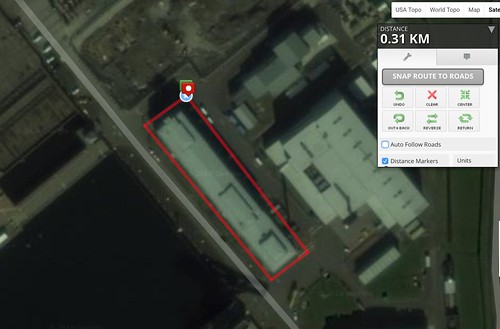
Download the GPX file. This contains the Lat/Long values of the route
If you try to upload it to strava, it'll reject it as there's no timing data. So add it, using some from any real GPX trace as a reference point. Doesn't have to be valid time, just make it slow enough that Strava doesn't think you are driving and tell you off for cheating.
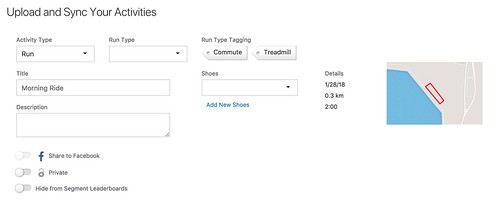
Upload the file as a run, creating a new activity
The next step is the devious one. "Create a segment", and turn part/all of the route into a Strava segment.
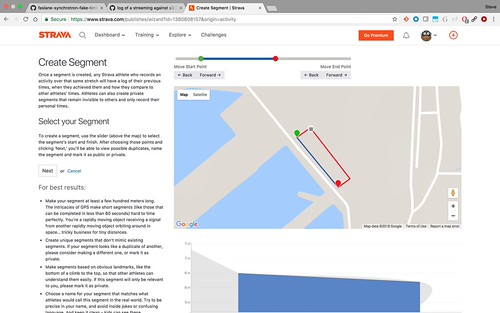
Once strava has gone through its records, you'll be able to see the overall top 10 runners per gender/age group, when they ran, it who they ran with. And, if their profile isn't locked down enough: which other military bases they've been for runs on.
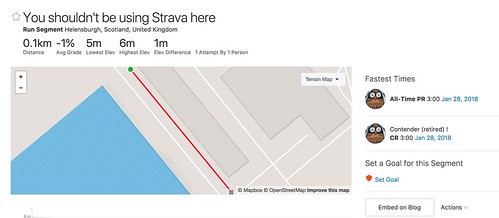
I have no idea who has done this run; whether there'll be any segment matches at all. If not, maybe the trace isn't close enough to the real world traces, everyone runs round clockwise, or, hopefully, people are smart enough to mark the area as a private. I'll leave strava up overnight to see what it shows, then delete the segment and run.
Finally, Berlin Buzzwords CFP is open, still offering to help with draft proposals. We can now say it's the place where Strava-based infosec issues were covered 2 years before it was more widely known.
Update 2018-01-29T21:13. I've removed the segment.
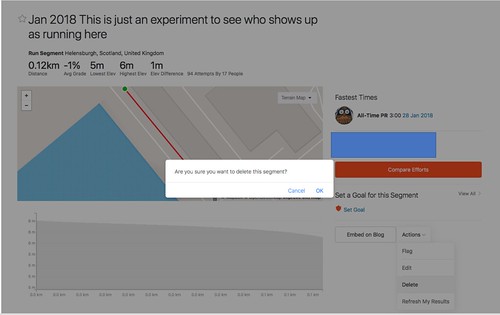
Some people's names were appearing there, showing that, yes, you can bootstrap from a heatmap to identification of individual people who have run the same route.
There's no need to blame the people here, so I've pulled the segment to preserve their anonymity. But as anyone else can do it, they should still mark all govt. locations where they train as private areas, so getting included from the heatmap and strava segments.
I don't know what Strava will do long term, but to stop it reoccurring, they'll need to have a way to mark an area as "private area for all users". Doable. Then go to various governments and say "Give us a list of secret sites you don't want us to cover". Which, unless the governments include random areas like mountain ranges in mid wales, is an interesting list of its own.
Update 2018-01-30T16:01 to clarify on marking routes private
- All ride/runs marked as "private" don't appear in the leader boards
- All ride/runs marked as "don't show in leader boards" don't appear
- Nor do any activities in a privacy zone make it onto a segment which starts/ends there
- But: "enhanced privacy mode" activities do. That is: even you can't see an individuals's activities off their profile, you can see the rides off the leaderboard.
Update 2018-01-31T00:30 Hacker News coverage
I have made Hacker news. Achievement Unlocked!
Apparently
This is neither advanced nor denanonymization (sic).
They basically pluck an interesting route from the hotmap (as per other people's recent discovery), pretend that they have also run/biked this route and Strava will show them names of others who run/biked the same way. That's clever, but that's not "advanced" by any means.
It's also not a deanonymization as there's really no option in Strava for public _anonymous_ sharing to begin with.
1. Thanks for pointing out the typo. Fixed.
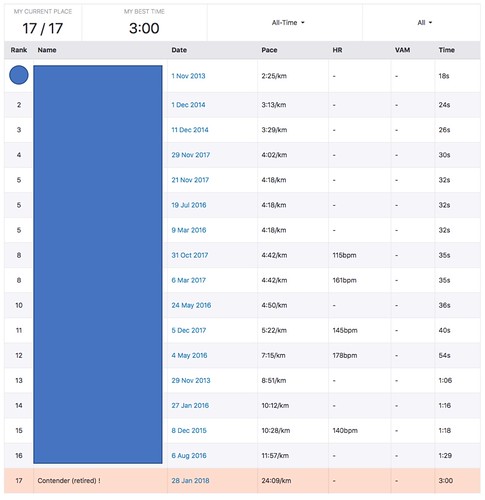
2. It's bootstrapping from nominally anon heatmap data to identifying the participants of the route. And unless people use nicknames (only 2 of the 16 in the segment above) did, then you reveal your real name. And as it shows the entire route when you click through the timestamp, you get to see where they started/finished, who if anyone they went with, etc, etc. You may not their real name, but you know a lot about them.
3. "It''s not advanced". Actually, what Strava do behind the scenes is pretty advanced :). They determine which of all recorded routes they match that segment, within 24h. Presumably they have a record of the bounds of every ride, so first select all rides whose bounds completely enclose the segment. Then they have to go through all of them to see if there is a fraction of their trail which matches.. I presume you'd go with the start co-ord and scan the trace to see if any of the waypoints *or inferred bits of the line between two recorded waypoints* is in the range of that start marker. If so, carry on along the trace looking for the next waypoint of the segment; giving up if the distance travelled is >> greater than the expected distance. And they do that for all recorded events in past history.
All I did was play around with a web UI showing photographs from orbiting cameras, adjacent to a map of the world with humanities' activities inferred by published traces of how phones, watches and bike computers calculated their positions from a set of atomic clocks, uploaded over the internet to a queue in Apache Kafka, processed for storage in AWS S3, whose consistency and throttling is the bane of my life and rendered via Apache Kafka, as covered in Strava Engineering. That is impressive work. Some of their analysis code is probably running through lines of code which I authored, and I'm glad to have contributed to something which is so useful, and, for the heatmap, beautiful to look at.
So no, I wasn't the one doing the advanced engineering —but I respect those who did, and pleased to see the work of people I know being used in the app.


