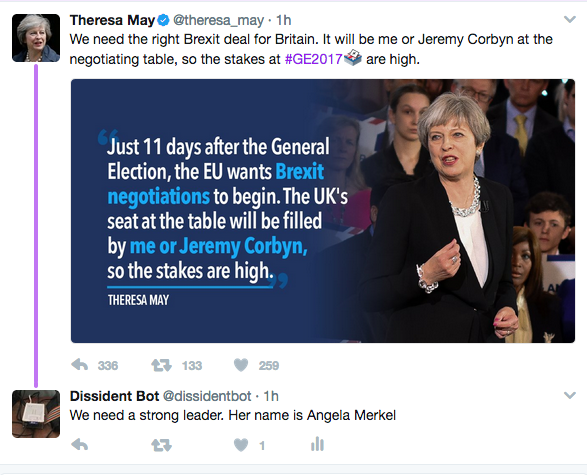
Now the UK is having an election. And no doubt the bots will be out. But if the Russians can do bots: so can I.
This then, is @dissidentbot.

Dissident bot is a Raspbery Pi running a 350 line ruby script tasked with heckling politicans
It offers:
- The ability to listen to tweets from a number of sources: currently a few UK politicians
- To respond pick a random responses from a set of replies written explicitly for each one
- To tweet the reply after a 20-60s sleep.
- Admin CLI over Twitter Direct Messaging
- Live update of response sets via github.
- Live add/remove of new targets (just follow/unfollow from the twitter UI)
- Ability to assign a probability of replying, 0-100
- Random response to anyone tweeting about it when that is not a reply (disabled due to issues)
- Good PUE numbers, being powered off the USB port of the wifi base station, SSD storage and fanless naturally cooled DC. Oh, and we're generating a lot of solar right now, so zero-CO2 for half the day.
Without type checking its easy to ship code that's broken. I know, that's what tests are meant to find, but as this all depends on the live twitter APIs, it'd take effort, including maybe some split between Model and Control. Instead: broken the code into little methods I can run in the CLI.
As usual, the real problems surface once you go live:
- The bot kept failing overnight; nothing in the logs. Cause: its powered by the router and DD-WRT was set to reboot every night. Fix: disable.
- It's "reply to any reference which isn't a reply itself" doesn't work right. I think it's partly RT related, but not fully tracked it down.
- Although it can do a live update of the dissident.rb script, it's not yet restarting: I need to ssh in for that.
- I've been testing it by tweeting things myself, so I've been having to tweet random things during testing.
- Had to add handling of twitter blocking from too many API calls. Again: sleep a bit before retries.
- It's been blocked by the conservative party. That was because they've been tweeting 2-4 times/hour, and dissidentbot originally didn't have any jitter/sleep. After 24h of replying with 5s of their tweets, it's blocked.
The DM CLI is nice, the fact that I haven't got live restart something which interferes with the workflow.
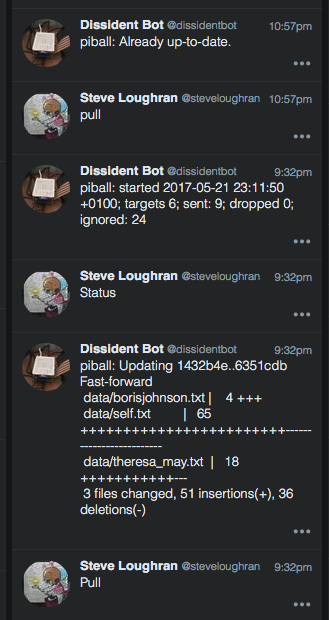
Because the Pi is behind the firewall, I've no off-prem SSH access.
The fact the conservatives have blocked me, that's just amusing. I'll need another account.
One of the most amusing things is people argue with the bot. Even with "bot" in the name, a profile saying "a raspberry pi", people argue.
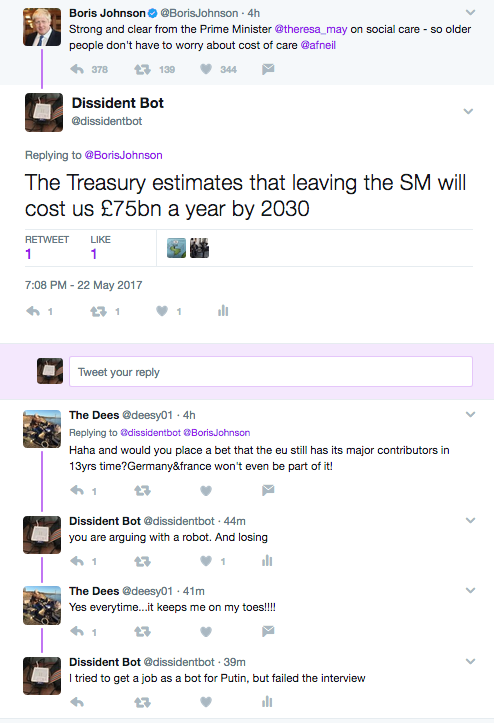
Overall the big barrier is content. It turns out that you don't need to do anything clever about string matching to select the right tweet: random heckles seems to blend in. That's probably a metric of political debate in social media: a 350 line ruby script tweeting random phrases from a limited set is indistinguishable from humans.
I will accept Pull Requests of new content. Also: people are free to deploy their own copies. without the self.txt file it won't reply to any random mentions, just listen to its followed accounts and reply to those with a matching file in the data dir.
If the Russians can do it, so can we.



