I laugh at Kerberos messages. When I see a stack trace with a meaningless network error I go "that's interesting". I even learned PowerShell in a morning to fix where I'd managed to break our Windows build and tests.
But there is now one piece of software I do not ever want to approach, ever again. Apple icloud billing.
So far, since Saturday's warnings on my phone telling me that there was a billing problem
- Tried and repeatedly failed to update my card details
- Had my VISA card seemingly blocked by my bank,
- Been locked out of our Netflix subscription on account of them failing to bill a card which has been locked out by my may
- Had a chat line with someone on Apple online, who finally told me to phone an 800 number.
- Who are closed until office hours tomorrow
What am I trying to do? Set up iCloud family storage so I get a full resolution copy of my pics shared across devices, also give the other two members of our household lots of storage.
What have I achieved? Apart from a card lockout and loss of Netflix, nothing.
If this was a work problem I'd be loading debug level log files oftens of GB in editors, using regexps to delete all lines of noise, then trying to work backwards from the first stack trace in one process to where something in another system went awry. Not here though here I'm thinking "I don't need this". So if I don't get this sorted out by the end of the week, I won't be. I will have been defeated.
Last month I opted to pay £7/month for 2TB of iCloud storage. This not only looked great value for 2TB of storage, the fact I could share it with the rest of the family meant that we got a very good deal for all that data. And, with integration with iphotos, I could use to upload all my full resolution pictures. So sign up I did
My card is actually bonded to Bina's account, but here I set up the storage, had to reenter it. Where the fact that the dropdown menu switched to finnish was most amusing

With hindsight I should have taken "billing setup page cannot maintain consistency of locales between UI, known region of user, and menus" as a warning sign that something was broken.
Other than that, everything seemed to work. Photo upload working well. I don't yet keep my full photoset managed by iPhotos; it's long been a partitionedBy(year, month) directory tree built up with the now unmaintained Picasa, backed up at full res to our home server, at lower res to google photos. The iCloud experience seemed to be going smoothly; smoothly enough to think about the logistics of a full photo import. One factor there
iCloud photos downloader works great as a way of downloading the full res images into the year/month layout, so I can pull images over to the server, so giving me backup and exit strategies.
That was on the Friday. On the Saturday a little alert pops up on the phone, matched by an email

Something has gone wrong. Well, no problem, over to billing. First, the phone UI. A couple of attempts and no, no joy. Over to the web page
Ths time, the menus are in german
"Something didn't work but we don't know what". Nice. Again? Same message.
Never mind, I recognise "PayPal" in german, lets try that:
No: failure.
Next attempt: use my Visa credit card, not the bank debit card I normally use. This *appears* to take. At least, I haven't got any more emails, and the photos haven't been deleted. All well to the limits of my observability.
Except, guess what ends up in my inbox instead? Netflix complaining about billing
Hypothesis: repeated failures of apple billing to set things up have caused the bank to lock down the card, it just so happens that Netflix bill the same day (does everyone do the first few days of each month?), and so: blocked off. That is, Apple Billing's issues are sufficient to break Netflix.
Over to the bank, review transactions, drop them a note.
My bank is fairly secure and uses 2FA with a chip-and-pin card inserted into a portable card reader. You can log in without it, but then cannot set up transfers to any new destination. I normally use the card reader and card. Not today though, signatures aren't being accepted. Solution, fall back to the "secrets" and then compose a message
Except of course, the first time I try that, it fails
This is not a good day. Why can't I just have "Unknown failure at GSS API level". That I can handle. Instead what I am seeing here is a cross-service outage choreographed by Apple, which, if it really does take away my photos, will even go into my devices.
Solution: log out, log in. Compose the message in a text editor for ease of resubmission. Paste and submit. Off it goes.
Sunday: don't go near a computer. Phone still got a red marker "billing issues", though I can't distinguish from "old billing issues" from new billing issues. That is: no email to say things are fixed. At the same time, no emails to say "things are still broken". Same from netflix, neither a success message, or a failure one. Nothing from the bank either.
Monday: not worrying about this while working. No Kerberos errors there either. Today is a good day, apart from the thermostat on the ground floor not sending "turn the heating" on messages to the boiler, even after swapping the batteries.
After dinner, netflix. Except the TV has been logged out. Log in to netflix on the web and yes, my card is still not valid. Go to the bank, no response there yet. Go back to netflix, insert Visa credit card: its happy. This is good, as if this card started failing too, I'd be running out of functional payment mechanisms.
Now, what about apple?

No, not english, or indeed, any language I know how to read. What now?
Apple support, in the form of a chat
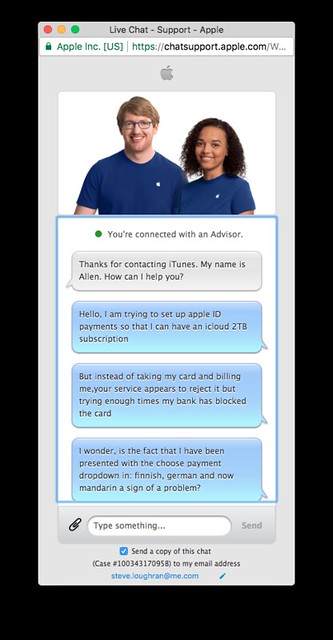
After a couple of minutes wait I as talking to someone. I was a bit worried that the person I'm talking to was "allen". I know Allen. Sometimes he's helpful. Let's see.
After explaining my problem and sharing my appleId, Allen had a solution immediately: only the nominated owner of the family account can do the payment, even if the icloud storage account is in the name of another. So log in as them and try and sort stuff out there.
So: log out as me, long in as B., edit the billing. Which is the same card I've been using. Somehow, things went so wrong with Amazon billing trying to charge the system off my user ID and failing that I've been blocked everywhere. Solution: over to the VISA credit card. All "seems" well.
But how can I be sure? I've not got any emails from Apple Billing. The little alert in the settings window is gone, but I don't trust it. Without notification from Apple confirming that all is well, I have to assume that things are utterly broken. How can I trust a billing system which has managed to lock me out of my banking or netflix?
I raised this topic with Allen. After a bit of backwards and forwards, he gave me an 800 number to call. Which I did. They are closed after 19:00 hours, so I'll have to wait until tomorrow. I shall be calling them. I shall also be in touch with my bank.
Overall: this has been, so far, an utter disaster. Its not just that the system suffers from broken details (prompts in random languages), and deeply broken back ends (whose card is charged), but it manages to escalate the problem to transitively block out other parts of my online life.
If everything works tomorrow, I'll treat this as a transient disaster. If, on the other hand, things are not working tomorrow, I'm going to give up trying to maintain an iCloud storage account. I'll come up with some other solution. I just can't face having the billing system destroy the rest of my life.

